Database : Transactions & Concurrency
Databases concurrency and transactions
A group of SQL statements that together form a unit of work is called a transaction. So, all the statements need to run successfully else the whole transaction fails.
For example, say if there is a cash movement between A and B, then A’s account needs to be debitted and B’s account needs to be credited at the same time. Both these steps need to be done in a transaction as it represents the action of one person paying the other.
Use transactions when multiple changes need to be made to the database and we want all these changes to complete or fail together.
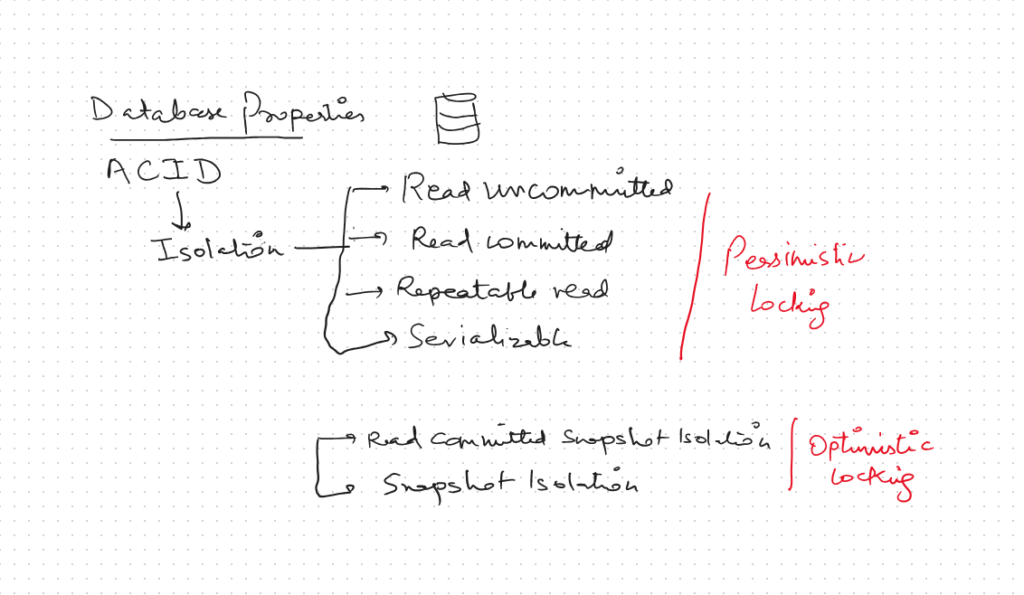
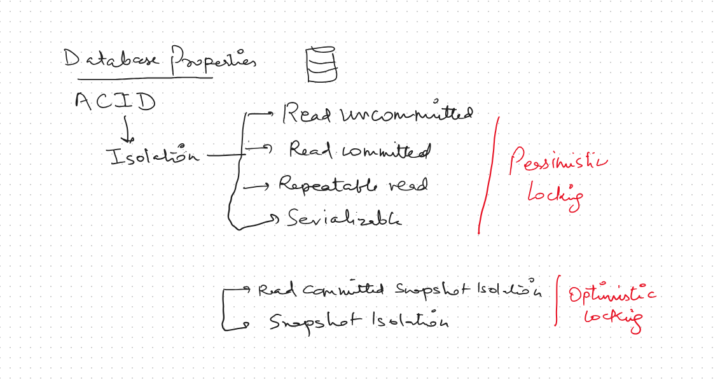
Properties of a transaction (ACID)
Atomicity refers to the transactions being unbreakable. Either all the SQL statements get executed and the transaction is committed or the whole transaction is rolled back in case one of the SQL statements fail.
Consistency refers to the property of our database always being in the consistent state. So a debit account action will always have a corresponding credit action.
Isolation refers to the fact each transaction is protected. If two transactions try to modify the same data then they cannot interfere with each other. If multiple transactions try to update the same data, the rows that are affected get locked so that only one transaction at a time can affect those rows. Other transactions will have to wait for that transaction to complete.
Durability refers to the fact that once a transaction has been committed, the changes made are permanent. Any system failure or crash will not affect the changes made by the committed transaction.
Understanding locking with an example
In SSMS, connect to a database and open three sessions i.e. three separate tabs.
So, in this example, we have a table called order_instruction_data.sql which has a column called security_name. As a first step, run the below for a data row that updates the security_name value to “test” in the first tab.
update order_instruction_data
set security_name = 'test'
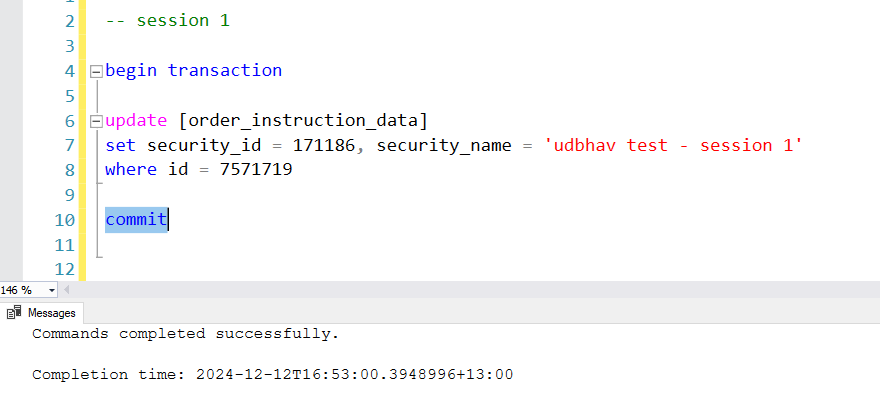
where id = 7571719Now in the second session tab, select the begin transaction and update-set-where statement block and run it. Don’t run the “commit” statement just yet. This should execute the statement as shown in the image.
begin transaction
update [order_instruction_data]
set security_id = 171186, security_name = 'udbhav test - session 1'
where id = 7571719
commit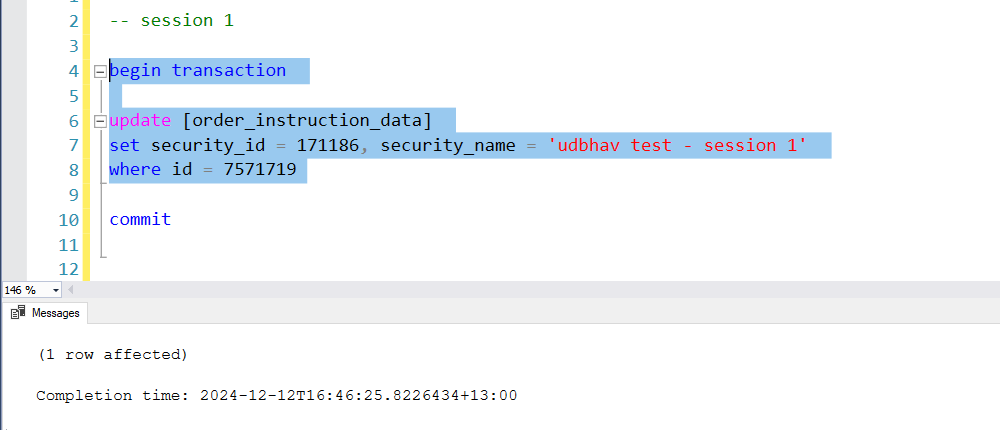
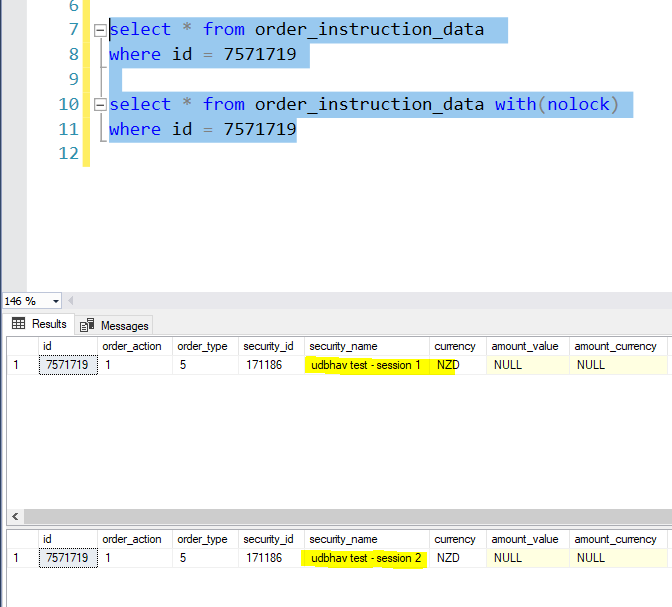
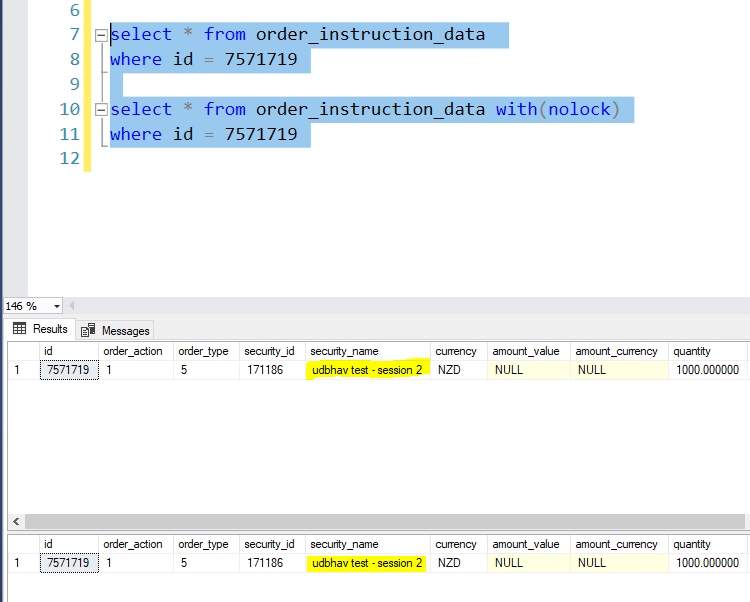
Query the table to ensure, with(nolock) yields “udbhav test – session 1” as result.
select * from order_instruction_data
where id = 7571719
select * from order_instruction_data with(nolock)
where id = 7571719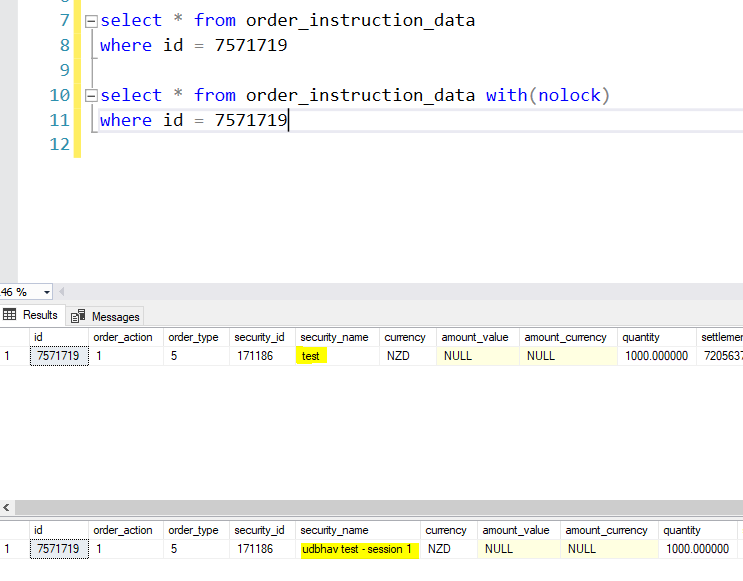
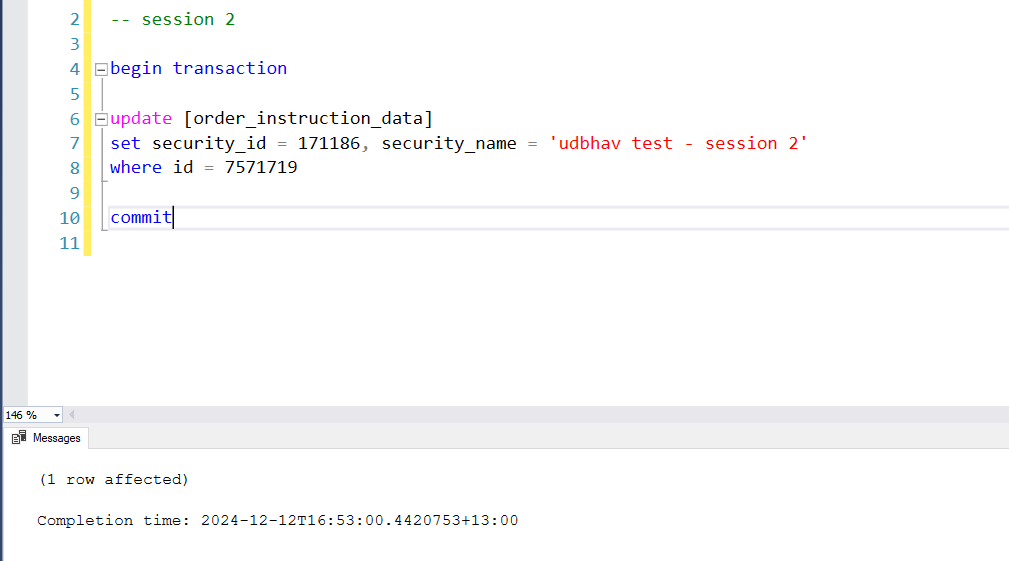
Now in the third session tab, run the same selected statements as shown in the image above again. Since the session 2 above has already acquired a lock on the row, this action will not execute immediately and keep spinning until either session 2’s transaction is committed or timeout happens in session 3.
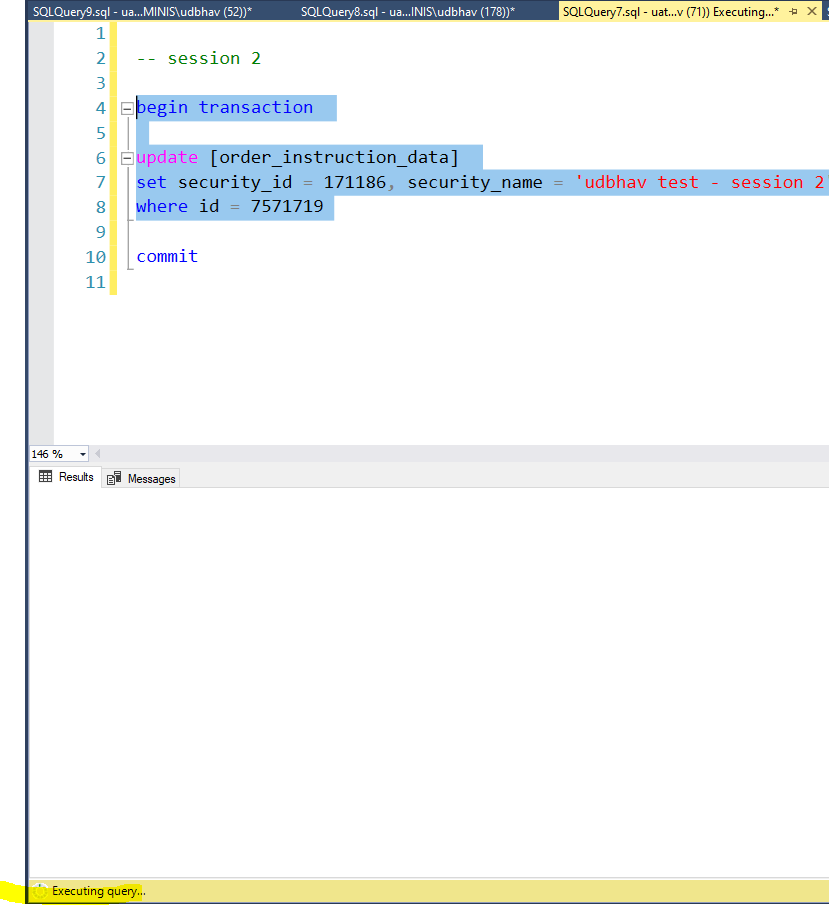
Now run the commit statement in session 2. This should execute session 3 as well if it was waiting.
Now before committing session 2, query the table again for values with and without lock. You should see, with(nolock) it is session 2’s name and without it, it is session 1’s name.
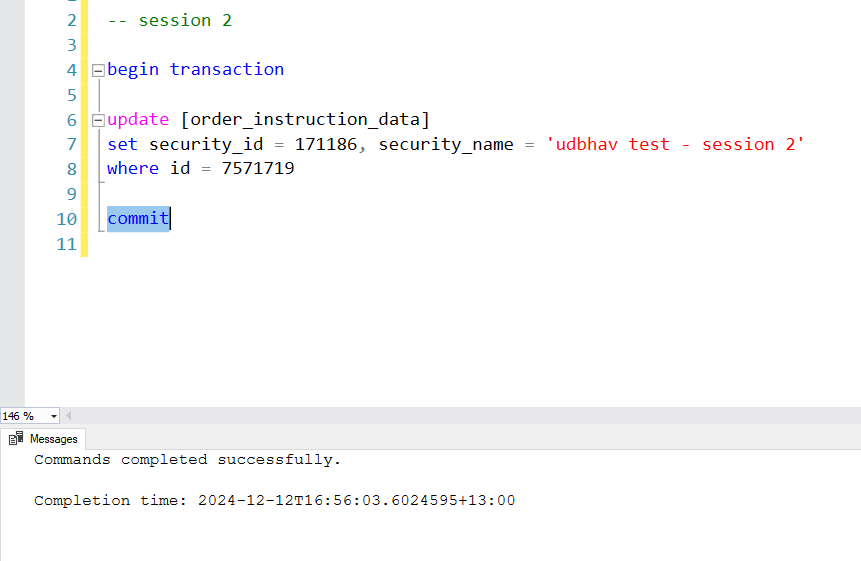
Now commit session 2 and re-query the table with and without lock. Both the queries should return session 2’s name.
Problems arising from concurrency
Lost updates
If two transactions try to update the same investor data, then the transaction that commits last will overwrite the changes made by the previous transaction. For example, say two transactions want to update the investor information where one wants to update the country and the second wants to update the tax rate.
--- Starting point ----
{ "John Doe", "New Zealand", "17.5%"}
--- Transaction 1 wants to update the record to ---
{ "John Doe", "India", "17.5%"}
--- Transaction 2 wants to update the record to ---
{ "John Doe", "New Zealand", "28%"} To prevent losing data from happening, we use locks. A transaction will acquire a lock and until it is released, the second transaction will not be able to acquire a lock and make changes to the same data.
Dirty reads
It happens when a transaction reads uncommitted data. For example, suppose two separate processes are running concurrently where the first process attempts to update an investor’s tax rate to 28% and the other process attempts to read the tax rate value to calculate the tax against a sell stock order.
So, if the second transaction goes ahead and reads the value of the investor’s tax rate before the first transaction is committed and say, for some reason the first transaction errors out and has to be rolled back, then the second transaction has read an incorrect value that never existed and thus calculated an incorrect tax amount to be paid. So, in this case we have read dirty uncommitted data.
--- Transaction A -----
BEGIN TRANSACTION
...
UPDATE investor
SET tax_rate = 0.28
WHERE investor_id = 12345
...
COMMIT
--- Transaction B -----
BEGIN TRANSACTION
...
SELECT tax_rate FROM investor
WHERE investor_id = 12345
...
COMMITTo solve this problem, we need to isolate each transaction such that data modified by one transaction is not immediately available to the other transactions. SQL defines four isolation levels. READ COMMITTED isolation level ensures only committed data is read by other transactions.
Non-repeatable (inconsistent) reads
This happens when during the course of a transaction we read something twice but get different results. Continuing with the previous example, suppose two separate processes are running concurrently where the first process attempts to read the tax rate value (say it is 28%) to first calculate the tax against a sell stock order and post it and then if the tax rate is above a certain value (say 30%) then adds an extra GST to it. And before reading the tax rate again for GST posting, the second transaction updates the investor’s tax rate to 33%. Now, in this scenario we have inconsistent read of the investor’s tax rate for the two calculation in the same transaction.
--- Transaction A -----
BEGIN TRANSACTION
SELECT tax_rate FROM investor WHERE investor_id = 12345
... Tax calculation
SELECT tax_rate FROM investor WHERE investor_id = 12345
... GST calculation
COMMIT
--- Transaction B -----
BEGIN TRANSACTION
UPDATE investor
SET tax_rate = 0.28
WHERE investor_id = 12345
COMMITTo solve this, the SQL standards define another increased isolation level called REPEATABLE READ. The reads are repeatable and consistent in the transaction and other transaction’s changes are not visible to our transaction. We will see the snapshot established by the first read.
Phantom Reads
Suppose there is a service level agreement (SLA) with an advisory client where at market close (say 5 PM on business days), we need to give the update of each investor’s tax rate that belong to the client. And suppose the client then uses this information to calculate daily costs incurred to post it to investor’s account.
So, for the business it is of extreme importance that the investor data is the latest. And suppose an investor with id 66 has applied to move his account from his current client to client with id 12345 which is processing at the same moment concurrently and suppose this transaction completes first.
Thus, after transaction A completes, we will still have an investor that should have been reported but we will miss it. This is called a phantom or ghost read where data suddenly appears or is removed after we execute our query.
--- Transaction A -----
BEGIN TRANSACTION
SELECT investor_name, tax_rate FROM investors WHERE client_id = 12345
...
COMMIT
--- Transaction B -----
BEGIN TRANSACTION
UPDATE investors
SET client_id = 12345
WHERE investor_id = 66
COMMITTo solve this critical problem, we need to ensure no other transactions are running concurrently that can impact our query. We use another isolation level called SERIALIZABLE and it guarantees that our transaction is aware of other transactions that are being made to the same data and it waits for them to get completed.
This is the highest isolation level and gives the most certainty to our operations. But there is a trade-off. The more users and concurrency we have, the more wait and thus the more impact on performance. Hence, it is important to have this isolation level in cases where it is critical to not have phantom reads.
Summary
| Lost updates | Dirty reads | Non-repeatable reads | Phantom reads | |
| When two transactions update the same row and the one that commits last overwrites the changes made by the previous one. | When we read uncommitted data. | When same data is read twice in a transaction but we get different results. | When we miss one or more rows in a query because another transaction is changing the data and we are not aware of those changes i.e. we are dealing with Phantoms or ghosts. | |
| READ UNCOMMITTED | ||||
| READ COMMITTED | PROTECTED | |||
| REPEATABLE READ | PROTECTED | PROTECTED | PROTECTED | |
| SERIALIZABLE | PROTECTED | PROTECTED | PROTECTED | PROTECTED |
| SNAPSHOT | PROTECTED | PROTECTED | PROTECTED | PROTECTED |
The difference between serializable and snapshot isolation levels is that serializable will lock row ranges involved in a transaction for complete isolation and can thus lead to performance degradation. Whereas, snapshot uses row versioning to maintain consistency without locking, resulting in better concurrency but at the cost of higher tempdb usage.
READ COMMITTED is the default isolation level in SQL server. Use the below to see the isolation level set for the database.
DBCC USEROPTIONS;
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- at session level
/*
Options
===============
READ UNCOMMITTED
READ COMMITTED
REPEATABLE READ
SNAPSHOT
SERIALIZABLE
*/
ALTER DATABASE YourDatabaseName SET ALLOW_SNAPSHOT_ISOLATION ON; -- at DB level 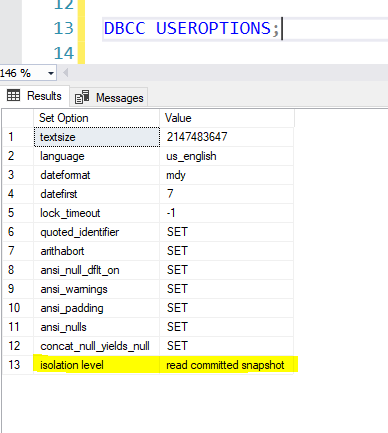
Below is an example of using the appropriate isolation level in a transaction in an application using C#.
using (var connection = new SqlConnection(connectionString))
{
connection.Open();
using (var transaction = connection.BeginTransaction(IsolationLevel.Serializable))
{
// Perform database operations within this transaction
transaction.Commit();
}
}Isolation levels in action
Read Uncommitted
This offers the lowest level of isolation and leads to all sorts of concurrency issues. To see this in action, start two sessions in SSMS.
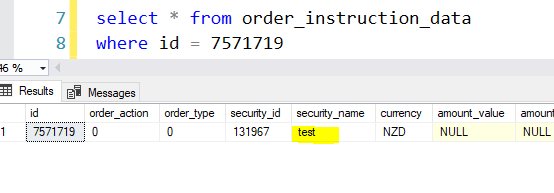
Run the query to first check what is the value of security_name field before we start the transactions.
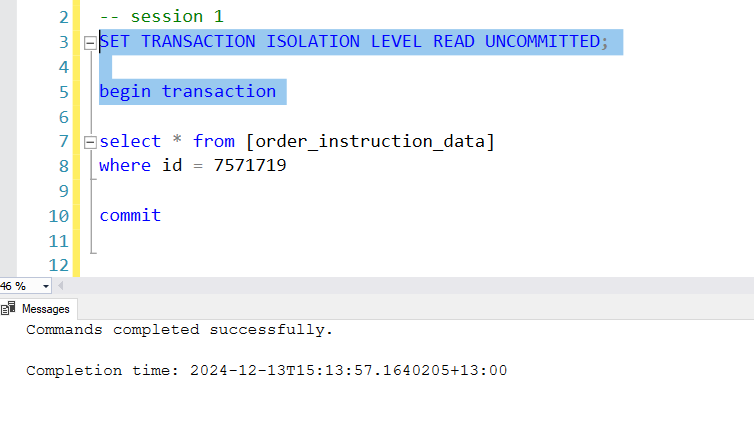
Step 1: In the first session run the set isolation level and begin transaction statements first.
Step 2: Now in the second session, run the begin transaction and update statement but don’t run the commit statement just yet.
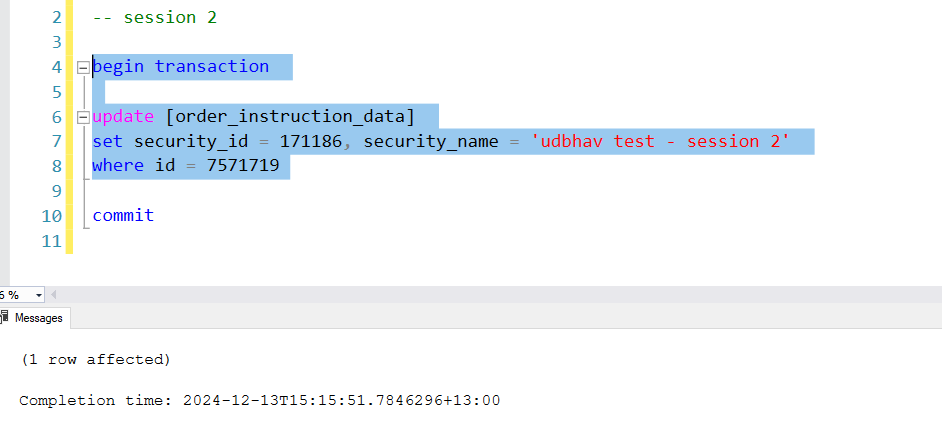
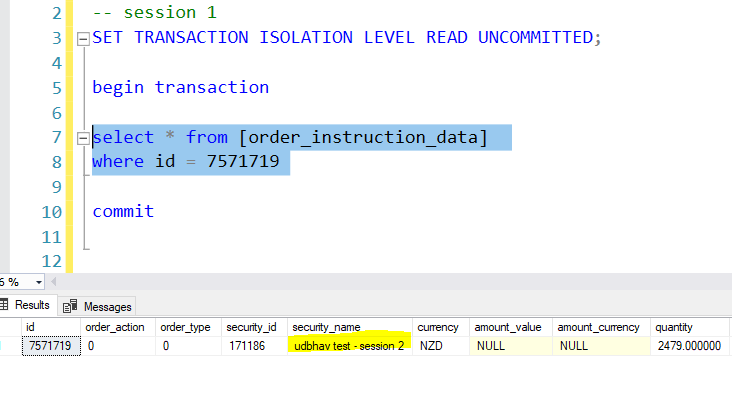
Step 3: Now go back to session 1, and execute the select statement. You would see the security_name value as updated by the session 2. So, even though the second transaction is not committed yet, the first transaction has read this value. If for any reason the second transaction needs to be rolled back, then we have a dirty read. Hence, with read uncommitted we may experience all sorts of concurrency problems as it is the lowest level of isolation.
Read Committed
This is the default isolation level in SQL server. To see this in action, start two sessions in SSMS.
Run the query to first check what is the value of security_name field before we start the transactions.
Step 1: In the first session run the set isolation level and begin transaction statements first.
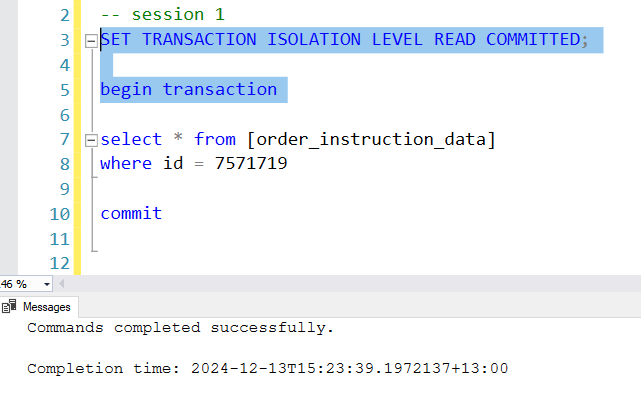
Step 2: Now in the second session, run the begin transaction and update statement but don’t run the commit statement just yet.
Step 3: Now go back to session 1, and execute the select statement. You would see the security_name value as still the same. So, the value in session 1 is not impacted yet by the update statement in the second transaction as it has not been committed yet.
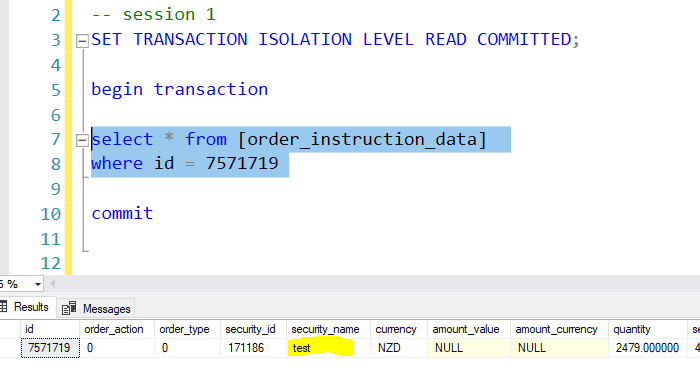
Thus, there is no dirty reads problem at this isolation level. However, we have the unrepeatable reads problem still. This would be more amplified when scripts are run in production where we want the exact number of rows being affected before and after, say, an update statement.
To replicate this problem, open two sessions. Let’s start with the security_name being test as shown below.
Now, in the first session assume the support team needs to update some fields. So, select until the first select statement and run.
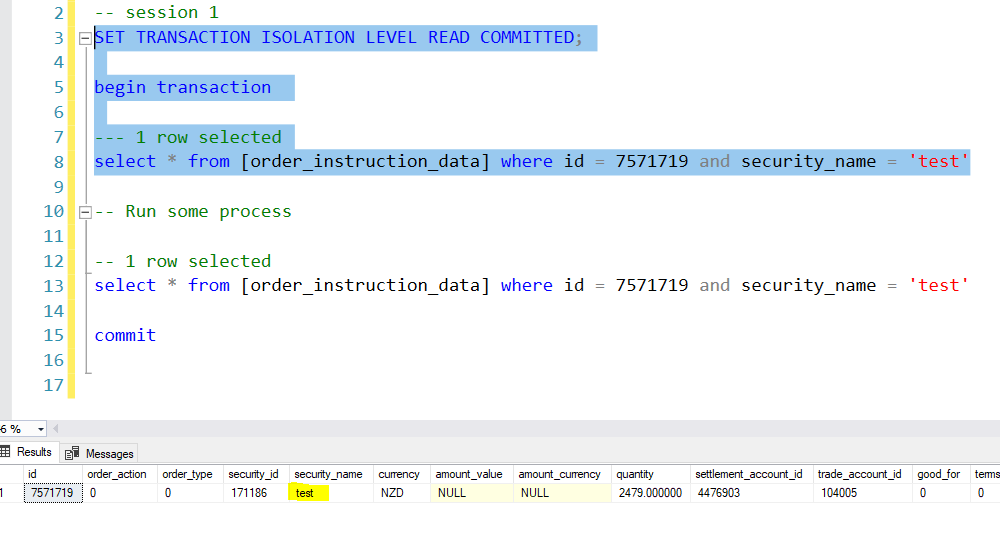
Now, run the second session which updates the security_name value of the row.
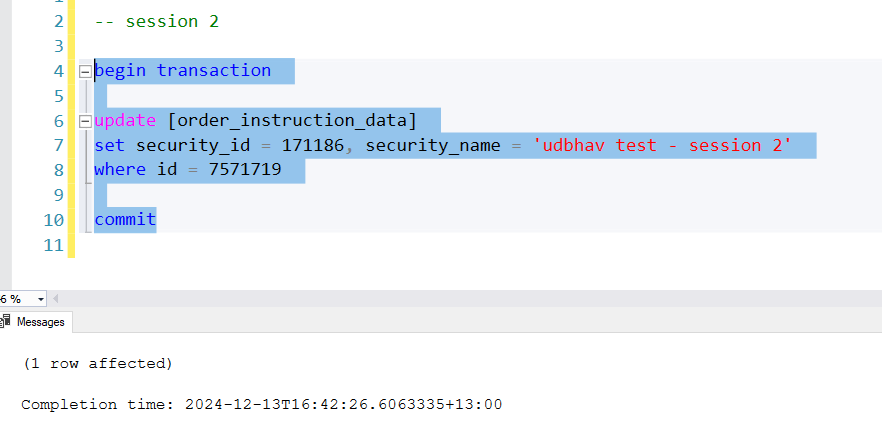
Now, go back to the second session and say, for audit reasons, we need to confirm that the script before and after returns the same number of rows. But it will not because of the isolation level we have set which does not cover repeatable reads.
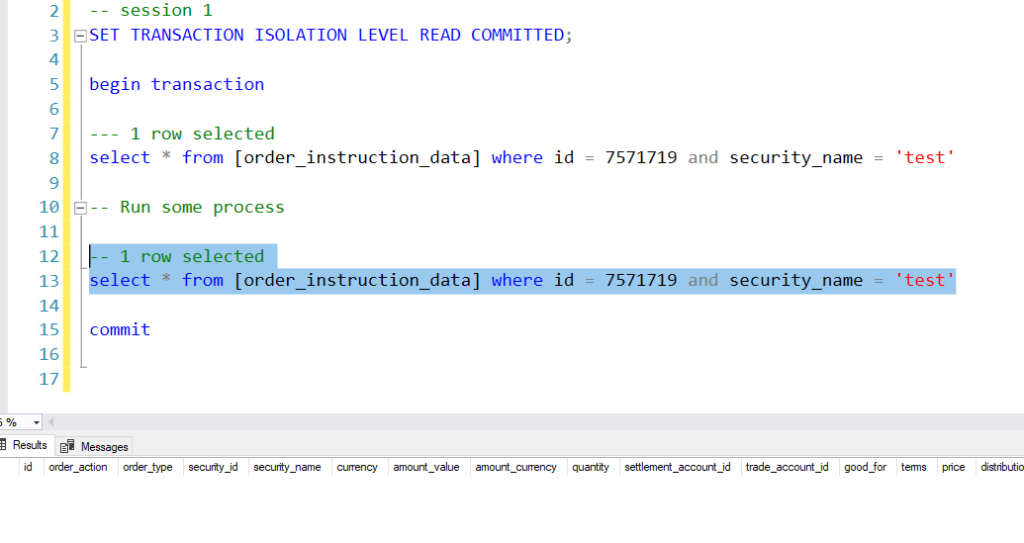
Repeatable Read
Picking up from where we left in the previous section. To see repeatable reads in action, start two sessions in SSMS.
Run the query to first check what is the value of security_name field before we start the transactions.
Step 1: In the first session run the set isolation level and begin transaction statements first.
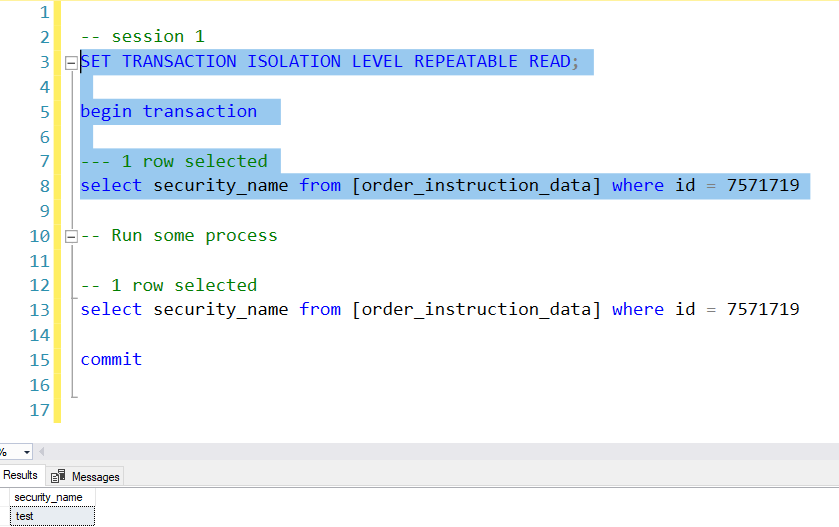
Step 2: Now in the second session, run the whole transaction. It will keep spinning and will not complete until the transaction in the first session has been committed or rolled back.
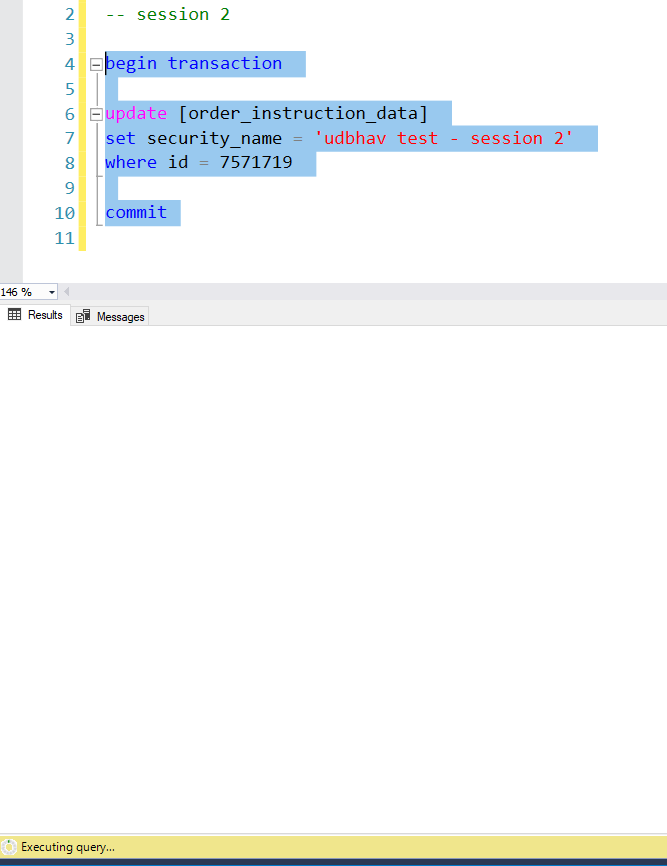
Step 3: Now go back to session 1, and execute the select statement. You would see the security_name value as still the same. So, the value in session 1 is not impacted.
In repeatable reads, the select query in SQL server places a shared lock (S) on the data row which is held until the transaction has been completed. The second session can re read the row but cannot make any updates as an exclusive lock (X) is required for that. Since an exclusive lock (X) cannot coexist with a shared lock (S), Session 2 is blocked until Session 1 commits or rolls back, releasing the lock.
Why does this not happen with READ COMMITTED?
In READ COMMITTED, the shared lock (S) acquired during the SELECT is released immediately after the query completes. Session 2’s UPDATE can acquire an exclusive lock (X) as soon as Session 1 finishes its SELECT, allowing the UPDATE to proceed. In REPEATABLE READ, the shared lock (S) is held for the entire duration of the transaction, blocking any modifications to the row.
| Isolation Level | Locks held during read | Duration of locks |
| READ COMMITTED | Shared (S) | Released immediately after the query. |
| REPEATABLE READ | Shared (S) | Held until transaction ends. |
| SERIALIZABLE | Shared (S) + Range locks | Held until transaction ends. |
REPEATABLE READ prevents non-repeatable reads (where a previously read row is modified by another transaction before the current transaction ends) by holding shared locks (S) on the rows it reads. However, it does not prevent phantom reads. This is because new rows can still be inserted by other transactions, and subsequent queries in the same transaction can return different result sets.
 Database : Transactions & Concurrency
Database : Transactions & Concurrency  Quick C# fundamentals revision
Quick C# fundamentals revision  SOLID Principles
SOLID Principles  Object Oriented Programming (OOP)
Object Oriented Programming (OOP)